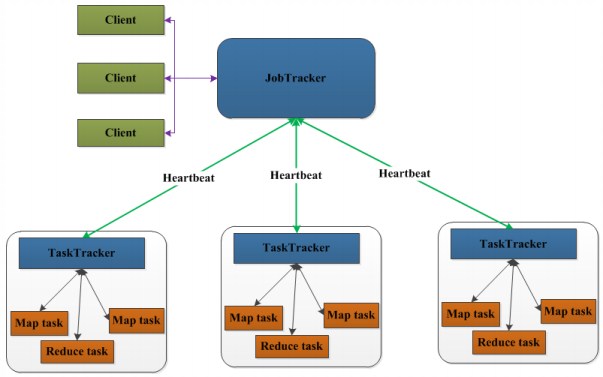
各个角色的功能:


2. MapReduce——容错性:
JobTracker
单点故障,一旦出现故障,整个集群不可用
TaskTracker
周期性向JobTracker汇报心跳
一旦出现故障,上面所有任务将被调度到其他节 点上
MapTask/ReduceTask
运行失败后,将被调度到其他节点上重新执行
3. MapReduce—资源组织方式:
机器用“slot”描述资源数量
由管理员配置slot数目(一般根据CPU,如一个cpu运行两个进程)
分为map slot和reduce slot两种, 从一定程度上,可看做“任务运行并发度”
Map slot
可用于运行Map Task的资源
每个Map Task可使用一个或多个map slot
Reduce slot
可用于运行ReduceTask的资源
每个Reduce Task可使用一个或多个reduce slot
4. MapReduce—TaskScheduler(任务调度)
基本作用
根据节点资源(slot)使用情况和作业的要求,将 任务调度到各个节点上执行
调度器考虑的因素
作业优先级
作业提交时间
作业所在队列的资源限制
作业调度流程图

5. MapReduce—数据本地性
什么是数据本地性(data locality)
如果任务运行在它将处理的数据所在的节点,则称该任务 具有“数据本地性”
本地性可避免跨节点或机架数据传输,提高运行效率
数据本地性分类
同节点(node-local)
同机架(rack-local)
其他(off-switch)

6. MapReduce—任务并行执行
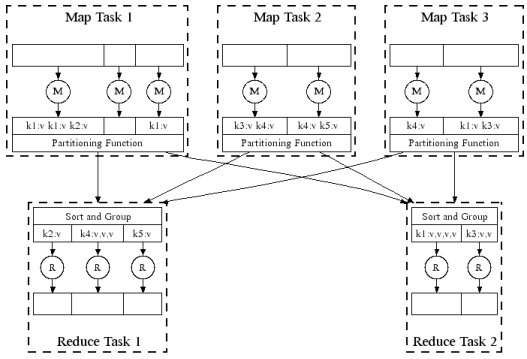
7. MapReduce—推测执行机制
作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map任务和Reduce任务构成, 因硬件老化、软件Bug等,某些任务可能运行非常慢
推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度
为拖后腿任务启动一个备份任务,同时运行
谁先运行完,则采用谁的结果
不能启用推测执行机制
任务间存在严重的负载倾斜
特殊任务,比如任务向数据库中写数据